
Classification dirigée fondée sur la vraisemblance maximale de Bayes
On peut substituer aux méthodes fondées sur des modèles, la définition de classes calculées à partir de l'image elle-même. Ces classes sont définies par un opérateur qui choisit des plages représentatives de la scène pour définir la valeur moyenne des paramètres de chaque classe reconnaissable (il s'agit donc d'une méthode dirigée). On utilisera avec profit une approche statistique quand la production des données est en bonne partie stochastique. La connaissance des statistiques des données (c'est à dire la distribution statistique théorique) permet d'utiliser une approche de classification basée sur la vraisemblance maximale de Bayes. Cette approche est optimale, la probabilité d'erreur de classement est, en moyenne, la plus basse de toutes les méthodes ![]() .
.
Une fois que l'on a défini les statistiques de classes, les échantillons de l'image sont classés en fonction de leur distance de la moyenne de la classe. On assigne à chaque échantillon la classe dont il est le moins éloigné. L'échelle des distances est calculée à partir de la règle de la vraisemblance maximale de Bayes.
C'est en 1988, que l'on a présenté cette méthode de classification des données polarimétriques tirées de radar à synthèse d'ouverture ![]() . Ses auteurs ont démontré que l'utilisation de l'ensemble complet des données polarimétriques garantissait une classification optimale. Toutefois, l'algorithme n'a été mis au point que pour les images radar singulières (ou mono-impulsion). Dans la plupart des cas en télédétection par radar, on obtient des données plurielles (données multivisées) pour réduire les effets du bruit des tavelures. Le nombre de visées est un paramètre important pour la création de modèles probabilistes.
. Ses auteurs ont démontré que l'utilisation de l'ensemble complet des données polarimétriques garantissait une classification optimale. Toutefois, l'algorithme n'a été mis au point que pour les images radar singulières (ou mono-impulsion). Dans la plupart des cas en télédétection par radar, on obtient des données plurielles (données multivisées) pour réduire les effets du bruit des tavelures. Le nombre de visées est un paramètre important pour la création de modèles probabilistes.
The full polarimetric information content is available in the scattering matrix S, the covariance matrix C, as well as the coherency matrix T. It has been shown that T and C are both distributed according to the complex Wishart distribution ![]() . The probability density function (pdf) of the averaged samples of T for a given number of looks, n, is
. The probability density function (pdf) of the averaged samples of T for a given number of looks, n, is
Toute l'information polarimétrique est contenue dans la matrice de diffusion, S, la matrice de covariance, C, et la matrice de cohérence, T. On a démontré ![]() que les matrices T et C sont distribuées selon une distribution de Wishart complexe. La fonction de densité de probabilité de la moyenne des échantillons de T pour un nombre donné de visées, n, est :
que les matrices T et C sont distribuées selon une distribution de Wishart complexe. La fonction de densité de probabilité de la moyenne des échantillons de T pour un nombre donné de visées, n, est :
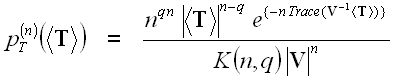 , (7.1)
, (7.1)
où
- <T> est la moyenne des échantillons de n visées de la matrice de cohérence,
- q est la dimensionnalité des données (3 s'il y a réciprocité, 4 pour les autres cas),
- Trace() est la somme des éléments diagonaux d'une matrice,
- V est la valeur espérée de la moyenne de la matrice de cohérence, E{<T>},
- K(n,q) est un facteur de normalisation.
Pour établir les statistiques de classification, on doit calculer la valeur moyenne de la matrice de cohérence pour chaque classe, Vm :
![]() , (7.2)
, (7.2)
où ![]() m représente l'ensemble des pixels de la classe m dans les données qui ont servi à l'entraînement du classificateur.
m représente l'ensemble des pixels de la classe m dans les données qui ont servi à l'entraînement du classificateur.
Selon la classification de vraisemblance maximale de Bayes, on peut calculer la distance d, à partir de ![]() :
:
![]() (7.3)
(7.3)
où le dernier terme tient compte des probabilités a priori, P(?m)![]() . L'accroissement du nombre de visées, n, diminue la contribution de la probabilité a priori. Toutefois, si l'on ne dispose d'aucune information sur les probabilités des classes pour une scène donnée, on peut supposer que les probabilités a priori de toutes les classes sont égales à zéro. Dans ce cas, on peut définir
. L'accroissement du nombre de visées, n, diminue la contribution de la probabilité a priori. Toutefois, si l'on ne dispose d'aucune information sur les probabilités des classes pour une scène donnée, on peut supposer que les probabilités a priori de toutes les classes sont égales à zéro. Dans ce cas, on peut définir ![]() une mesure appropriée de la distance :
une mesure appropriée de la distance :
![]() (7.4)
(7.4)
ce qui nous donne un classificateur de distance minimale indépendant du nombre de visées :
![]() (7.5)
(7.5)
Pour appliquer cette règle, on assigne un échantillon de l'image à une classe donnée, si la distance entre les valeurs des paramètres de cet échantillon et la moyenne de la classe est minimale. Puisque cette méthode est indépendante du nombre de visées, on peut l'utiliser pour des données multi-visées ou des données dont on a filtré les tavelures ![]() . On peut aussi généraliser cet outil de classement aux données multifréquences pour toutes les polarisations, si les fréquences sont suffisamment espacées pour assurer une indépendance statistique entre les bandes de fréquence
. On peut aussi généraliser cet outil de classement aux données multifréquences pour toutes les polarisations, si les fréquences sont suffisamment espacées pour assurer une indépendance statistique entre les bandes de fréquence ![]() .
.
La classification dépend de l'ensemble de données utilisées pour l'entraînement et doit donc être dirigée. Elle ne repose pas sur la physique des mécanismes de diffusion, ce qui peut constituer un désavantage. Elle exploite toutefois toute l'information polarimétrique et permet une classification des images indépendante du nombre de visées.
On peut aussi utiliser la méthode de classification de Bayes avec des données présentées sous la forme matrice de covariance. Nous avons utilisé la matrice de cohérence par souci d'uniformité avec notre présentation du classificateur H-A-![]() (cf. section précédente).
(cf. section précédente).
Détails de la page
- Date de modification :