
Un algorithme de classification mixte
Les méthodes dirigées et non dirigées que nous avons décrites plus haut ont chacune leurs faiblesses. Les seuils de la classification H-A-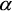 sont assez arbitraires et cette méthode n'exploite pas toute l'information polarimétrique, puisque l'on ne peut déterminer les quatre angles qui paramétrisent les valeurs propres. La technique de vraisemblance de Bayes exige l'utilisation d'un ensemble pour l'entraînement du programme ou un regroupement initial des données. Toutefois, chaque algorithme permet de combler les faiblesses de l'autre.
sont assez arbitraires et cette méthode n'exploite pas toute l'information polarimétrique, puisque l'on ne peut déterminer les quatre angles qui paramétrisent les valeurs propres. La technique de vraisemblance de Bayes exige l'utilisation d'un ensemble pour l'entraînement du programme ou un regroupement initial des données. Toutefois, chaque algorithme permet de combler les faiblesses de l'autre.
Une combinaison des deux algorithmes semblerait intéressante  . On obtiendra une meilleure classification en appliquant d'abord le classificateur H-A- non dirigé pour isoler et regrouper les 16 classes initiales, puis le classificateur à distance minimum, sur la base de la distribution des paramètres des regroupements. On pourra utiliser la distribution de Wishart complexe et des itérations pour optimiser les limites entre les classes , , .
. On obtiendra une meilleure classification en appliquant d'abord le classificateur H-A- non dirigé pour isoler et regrouper les 16 classes initiales, puis le classificateur à distance minimum, sur la base de la distribution des paramètres des regroupements. On pourra utiliser la distribution de Wishart complexe et des itérations pour optimiser les limites entre les classes , , .
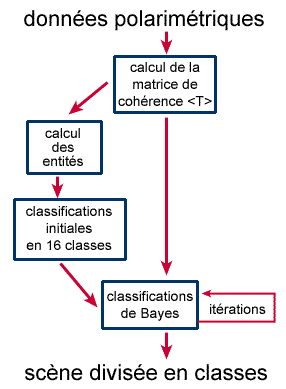
Figure 7-5 : Classificateur combiné H A 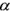 - distance minimum.
- distance minimum.
L'algorithme combiné est illustré à la figure 7-5. On peut le considérer comme un algorithme non dirigé, puisque la classification initiale n'est pas dirigée. Toutefois, puisque les itérations raffinent les moyennes et les frontières des regroupements, il est recommandé d'examiner les classes finales et de leur attribuer une description correspondant à une interprétation physique. On notera que bien que le regroupement initial ait été effectué dans l'espace H-A-, la classification suivant la distance minimum est réalisée en utilisant directement la matrice de cohérence. Après la classification de Bayes, il est possible que les regroupements se chevauchent dans l'espace H-A-. Puisque les résultats rendus par les classificateurs dépendent du nombre et de la diversité des classes déterminées à l'entrée du classificateur, il est toujours utile d'essayer plusieurs classes initiales.
La figure 7-6 donne un exemple des résultats de la méthode classification combinée. On a pu extraire de cette image prise par l'instrument SIR-C, en avril 1994, au large de la côte occidentale de Terre Neuve, quatre types de glace de mer, trois classes d'eau et quatre classes de terrain . Le degré de détails des types de glaces extraites est une indication de la puissance de la classification automatique des données polarimétriques.
Les algorithmes de classification peuvent contenir un algorithme de segmentation qui regroupe les pixels dont les caractéristiques sont communes avant de leur assigner une classe. Si elle est réalisée correctement, la segmentation pourra améliorer nettement les résultats de classification .

Le saviez-vous?<
On utilise plusieurs algorithmes de classification et on en élabore d'autres, parce que le succès d'un algorithme est très dépendant des caractéristiques des capteurs et même des entités qui composent la scène. Parmi les méthodes mises au point, on retrouve la méthode des composantes principales, l'estimation de vraisemblance maximale, les méthodes d'optimisation de Bayes, l'estimation a posteriori maximale, les méthodes de regroupement, les réseaux neuronaux, les méthodes de distances minimales et parallélépipédiques et les champs aléatoires de Markov.
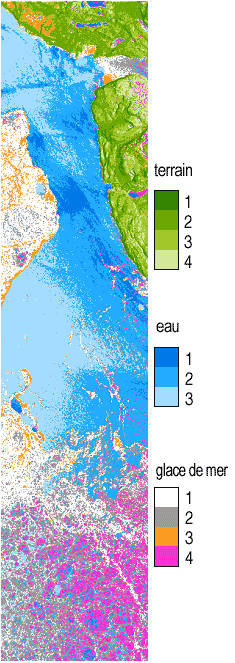
Figure 7-6 : Classification du terrain, de la mer et de la glace, dans une scène observée dans la bande C par le radar polarimétrique SIR-C, au large de la côte occidentale de Terre Neuve .
Détails de la page
- Date de modification :